인덱스란?
- 색인 : 쉽게 찾아볼 수 있도록 일정한 순서에 따라 놓은 목록
- 원하는 값을 빠르게 찾을 수 있음
- where 절을 통해서 검색할 수 있어야 인덱스가 사용됨
- 데이터베이스 테이블에 대한 검색 성능을 향상시키는 자료 구조이며, where 절 등을 통해서 활용됨
인덱스를 적용하지 않는다면?
- 100만건 이상의 데이터에서 이메일이 yn324@naver.com인 회원을 조회할 때 느리다
- 전체 데이터에서 순차적으로 확인하기 때문에!
- 데이터가 기준없이 저장된 상태이기 때문에 데이터가 특정 기준으로 정렬되어 있다면 검색을 빠르게 할 수 있음
인덱스 특징
- 인덱스는 항상 최신의 정렬상태를 유지함
- 인덱스도 하나의 데이터베이스 객체
- 데이터베이스 크기의 약 10% 정도의 저장공간 필요
인덱스 알고리즘
- 페이지 : 데이터가 저장되는 단위 (16 kbyte)
인덱스 알고리즘 : Full Table Scan

- 총 3개의 페이지를 거치고 12번 검색함
특징
- 순차적으로 접근
- 접근 비용 감소
사용하는 경우
- 적용 가능한 인덱스가 없는 경우
- 인덱스 처리 범위가 넓은 경우
- 크기가 작은 테이블에 엑세스하는 경우
참고 자료구조 : 이진 탐색 트리

- 모든 노드의 왼쪽 서브트리는 해당 노드의 값보다 작은 값들만 가지고, 모든 노드의 오른쪽 서브 트리는 해당 노드의 값보다 큰 값들만 가짐
- 20을 기준으로 봤을 때, 20보다 왼쪽 서브트리는 20보다 작고, 20보다 오른쪽 서브트리는 20보다 큼
- 자녀노드는 최대 2개까지 가질 수 있음
인덱스 알고리즘 : B-tree

- 자녀 노드의 최대 개수를 늘리기 위해서 부모 노드에 key를 하나 이상 저장함
- 부모 노드의 key들을 오름차순으로 정렬함
- 정렬된 순서에 따라 자녀 노드들의 key 값의 범위가 결정됨
- BST를 일반화한 tree
파라미터

- internal 노드의 key 수가 x개라면 자녀 노드의 수는 언제나 x+1개
- 모든 leaf 노드들은 같은 레벨에 있음 ⇒ 어떤 경우에도 시간복잡도가 O(logN)임
실제 인덱스에서의 B-Tree

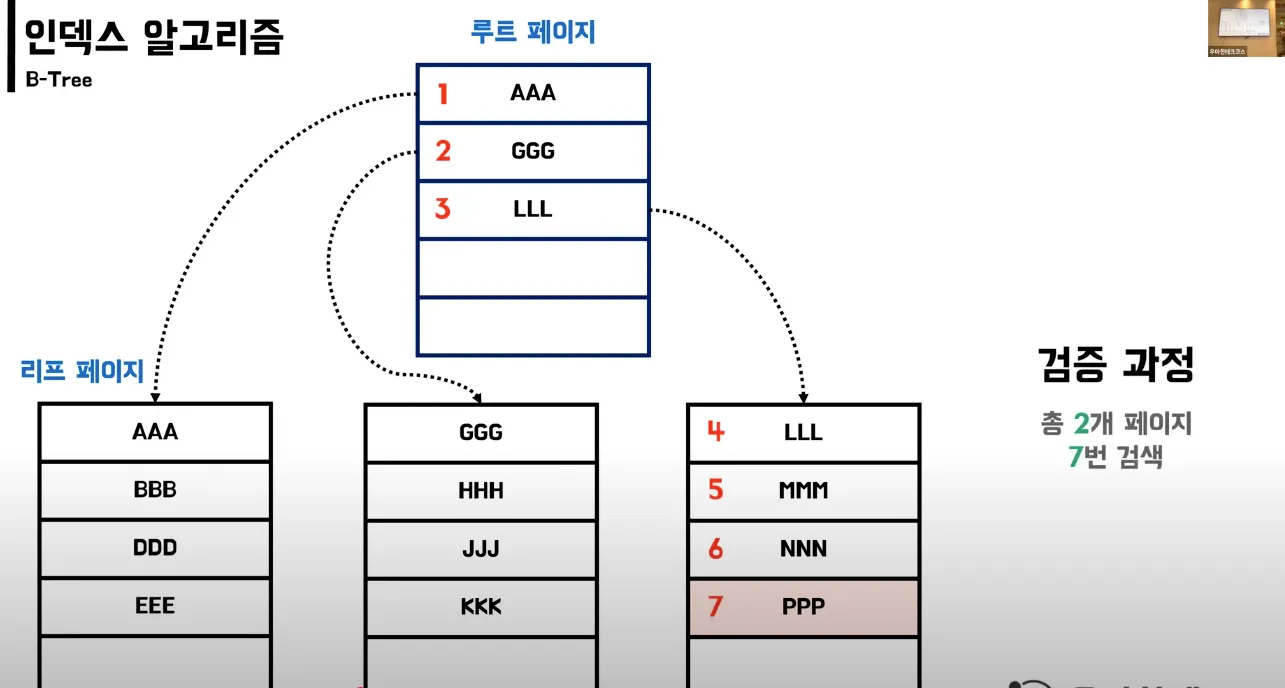
- 총 2개의 페이지를 거치고 7번 검색
⇒ 이를 통해 select의 성능이 향상됨
insert
- 페이지 분할이 발생하여 성능이 느려지게 됨
- 페이지 분할
- 페이지에 새로운 데이터를 추가할 여유공간이 없어 페이지에 변화가 발생
- DB가 느려지고 성능에 영향을 줌
delete
- 인덱스의 데이터를 실제로 지우지 않고 사용안함 표시를 함
update
- 가장 먼저 delete 수행 (기존 값 사용안함 표시)
- 그 다음 insert 수행 (변경된 값 삽입)
delete & update
- where절로 처리할 대상을 찾기 위한 조회 성능은 향상되지만,
- 사용하지 않는 인덱스가 적용되었다면 불필요한 처리량 증가
- 사용안함 표시로 페이지 낭비 및 인덱스 조각화 심해짐
- 인덱스 조각화 : 인덱스가 논리적으로 정렬되어 있지 않고, 물리적으로 비효율적으로 저장되어 있는 상태
결론
- select는 성능이 향상되지만 insert, delete, update는 페이지 분할과 사용안함 표시로 인덱스의 조각화가 심해져 성능이 저하됨
인덱스 종류

- pk를 걸면 자동으로 클러스터링 인덱스가 생김
- 하나의 컬럼에 not null과 unique 제약조건을 같이 걸어도 걸림
- unique 제약조건을 걸면 자동으로 논 클러스터링 인덱스가 생김
클러스터링 인덱스
- 실제 데이터와 같은 무리의 인덱스
- 실제 데이터가 정렬된 사진
- 실제 데이터 자체가 정렬
- 테이블당 1개만 존재 가능
- 리프 페이지가 데이터 페이지
- 아래 제약조건 시 자동 생성
- pk를 걸면 (우선순위 1위)
- not null + unique
클러스터링 인덱스 적용

논 - 클러스터링 인덱스
- 실제 데이터와 다른 무리의 별도의 인덱스
- 실제 데이터 탐색에 도움을 주는 별도의 찾아보기 페이지
- 실제 데이터 페이지는 그대로
- 별로의 인덱스 페이지 생성 → 추가 공간 필요
- 테이블당 여러 개 존재
- 리프 페이지에 실제 데이터 페이지 주소를 담고 있음
- 아래 제약조건 시 자동 생성
- unique 제약조건 적용시 자동 생성
- 직접 index 생성시 논-클러스터링 인덱스 생성
논 - 클러스터링 인덱스 적용
- 이름에 인덱스 걸음
- 리프페이지에서 이름을 기준으로 정렬된 모습을 보임

클러스터링 + 논클러스터링을 동시에 적용했을 때

- 데이터가 추가되거나 삭제될 때마다 인덱스페이지의 주소가 바뀌면 비효율적이기 때문에
- 논 클러스터링 인덱스의 리프 페이지에 실제 데이터 페이지 주소가 아닌 클러스터링 인덱스가 적용된 컬럼의 실제 값을 가지고 있음
인덱스 적용 기준
- 카디널리티 : 테이블에서의 행의 갯수, 요소의 갯수
- 디그리 : 테이블에서의 열의 갯수
- 카디널리티(그룹 내 요소의 개수)가 높은 것, 중복수치가 낮은 것에 걸어야 함!
- where, join, order by 절에 자주 사용되는 컬럼
- 인덱스는 추가 공간이 필요로 됨
- 조건 절이 없다면 인덱스가 사용되지 않음
- insert, delete, update 가 자주 발생하지 않는 컬럼
- 규모가 작지 않은 테이블
출처


