Redis 네이밍 컨벤션
- 콜론(:)을 활용해 계층적으로 의미를 구분해서 사용한다!
users:200:profile -> users 중에서 pk가 200인 user의 profile
캐시 (Cache)
- 원본 저장소보다 빠르게 데이터를 가져올 수 있는 임시 데이터 저장소
- 임시 저장소를 의미한다고 보면 됨
캐싱 (Caching)
- 캐시에 저장해서 데이터를 빠르게 가져오는 방식
- Cache Hit : 데이터를 요청했을 때 캐시에 데이터가 있는 경우
- Cache Miss : 데이터를 요청했을 때 캐시에 데이터가 없는 경우
캐싱전략
Cache Aside : 조회시에 캐시를 먼저 찌르고, 없으면 DB에서 조회하는 방식
데이터를 조회할 때 캐시에서 먼저 조회하고, 없으면 데이터베이스를 통해서 조회해오는 방식
1. 캐시에 데이터가 있을 경우 (= Cache Hit)
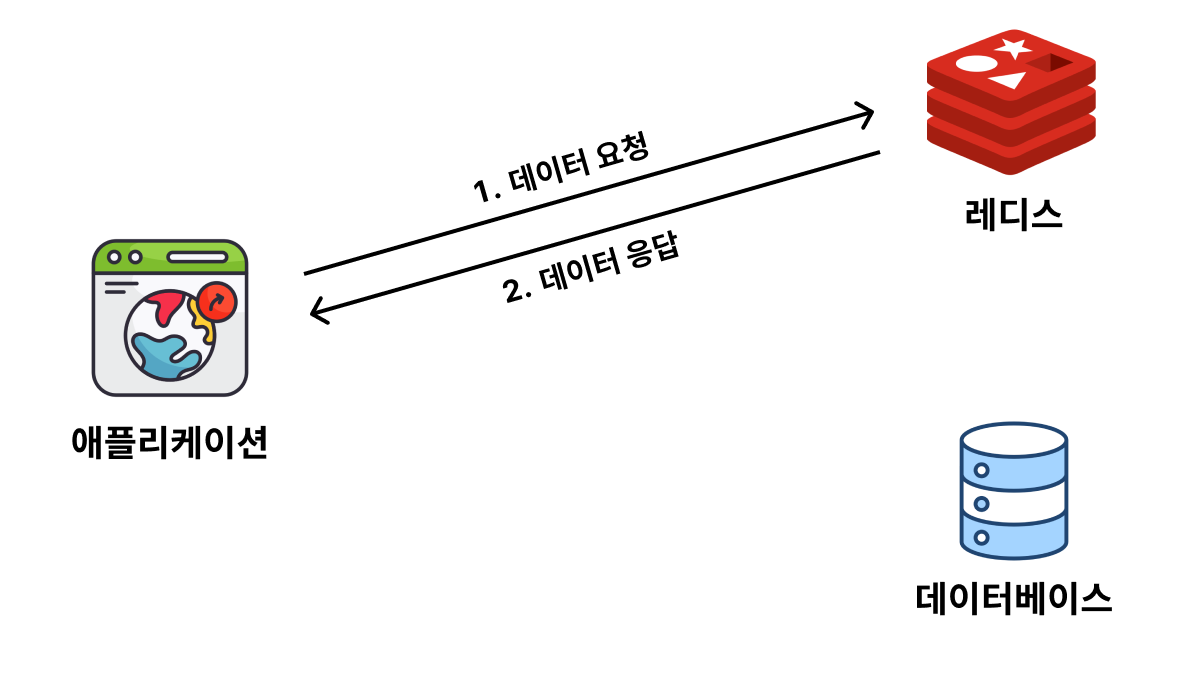
2. 캐시에 데이터가 없을 경우 (= Cache Miss)

White Around : 쓰기 작업(저장, 수정, 삭제)을 캐시에는 반영하지 않고, DB에만 반영
데이터를 저장, 수정, 삭제시에는 데이터베이스에만 수행
조회시에 Redis에 데이터가 없으면 데이터베이스로부터 데이터를 조회해와서 Redis에 저장시켜줌
Cache Aside, Write Around 전략의 한계점
- 캐시된 데이터와 DB 데이터가 일치하지 않음 → 데이터의 일관성을 보장할 수 없음 → 데이터를 수정할때 데이터베이스의 값만 업데이트하기 때문
- 캐시에 저장할 수 있는 공간이 적음
Cache Aside, White Around 의 한계점 극복 방법 : TTL 설정
- 데이터를 업데이트할 때마다 레디스도 업데이트하면 성능적으로 느려진다 → 데이터 조회 성능 개선 목적으로 적용한 레디스가 의미없어짐
- 그렇기에 1. 자주 조회되고 2. 잘 변하지 않고 3. 정확하게 실시간으로 일치하지 않아도 되는 데이터를 기준으로 캐시 전략을 사용
- 하지만 장시간동안 동기화되지 않으면 문제 생김 → TTL(만료 시간 설정 기능)으로 극복 → 시간이 지나면 레디스에서 데이터가 사라지므로 디비에서 업데이트 된 데이터 조회하고 레디스에 넣어서 해결!
- 저장할 수 있는 공간이 적은 캐시를 → TTL로 인해서 비워주기 떄문에 효율적으로 공간을 사용할 수 있음
Throughput 비교를 통한 캐싱 적용 전후의 성능 비교
Throughput : 1초당 처리한 트랜잭션(API 요청)의 수
→ 내 서비스가 1초당 100개의 API요청을 처리할 수 있으면 이 서비스의 Throughput은 100 TPS
30명이 10초동안 요청을 계속 보낸다고 가정하자
k6 run --vus 30 --duration 10s script.js캐시 적용 전
이 서비스가 1초에 최대 요청할 수 있는 요청 수는 17.6개의 요청이다
-> Throughput = 17.6개

캐시 적용 후
이 서비스가 1초에 최대 요청할 수 있는 요청 수는 3753개의 요청이다
-> Throughput = 3753개
결론 : 213배 빨라졌다!
'Redis' 카테고리의 다른 글
| Spring에 Redis적용하기 (0) | 2025.03.31 |
|---|---|
| Redis의 정의와 기본 명령어 (1) | 2025.03.25 |
