100만건 생성 테스트
첫 번째 시도 : NoSuchBeanDefinitionException
- jpa로 save를 100만건 시도
@DataJpaTest
class UserRepositoryTest {
@Autowired
private UserRepository userRepository;
@Test
void 유저_데이터를_100만_건_생성() {
for (long i = 0L; i < 1000000; i++){
String email = "user" + i + "@example.com";
String password = "securePassword123";
UserRole role = UserRole.of("ROLE_USER");
String nickName = UUID.randomUUID().toString().substring(0, 8);
User user = new User(email, password, role, nickName);
userRepository.save(user);
}
}
}
-> NoSuchBeanDefinitionException 발생
EntityManager를 찾을 수 없다고 한다
테스트 패키지 하위에 config 파일을 만들고 해결
@TestConfiguration // 테스트 환경 전용 설정
public class TestQuerydslConfig {
@PersistenceContext
private EntityManager entityManager;
@Bean
public JPAQueryFactory jpaQueryFactory() {
return new JPAQueryFactory(entityManager);
}
}
두 번째 시도 : JdbcSQLSyntaxErrorException
Caused by: org.h2.jdbc.JdbcSQLSyntaxErrorException: Table "TODOS" not found; SQL statement:
생성된 쿼리를 보니 동일한 테이블을 생성하는 쿼리가 여러번 날라가면서 SyntaxErrorException이 계속 뜬다
원인
- 기본적으로 설정된 테스트용 h2 데이터베이스
- 따로 설정해둔 properties 파일이 적용되지 않음
현재 나는 테스트용 데이터베이스를 mysql애 연결하고 싶어서 설정파일을 따로 빼놓았는데 자동으로 h2로 실행하려 해서 mysql과 호환이 안되서 그런 것 같다
h2 의존성 주석 처리
compileOnly 'org.projectlombok:lombok'
// runtimeOnly 'com.h2database:h2'
runtimeOnly 'com.mysql:mysql-connector-j'
테스트용 poroperties 경로

이렇게 두면 자동으로 테스트할 때 적용되는 줄 알았는데 아니었다🙄
테스트 클래스에 테스트용 poroperties 설정파일을 적용하는 어노테이션 적용
@TestPropertySource(locations = {"classpath:/application-test.properties"})
실제 데이터베이스에 데이터를 저장하기 위한 설정 적용
UserRepositoryTest 클래스 상단에 써준다.
- @SpringBootTest를 붙이면 자동으로 테스트가 끝나고 롤백이 되기 때문에 @Rollback(false)를 붙여준다
- 실제 데이터베이스에 적용할 것이기 때문에 @AutoConfigureTestDatabase의 설정을 적용해준다
@Rollback(false)
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
세 번째 시도 : OutOfMemoryError
아무래도 저렇게 save를 백만개 시도하면 데이터 베이스 입출력이 백만번 수행되는거다보니 시간이 매우 오래걸린다고 한다 (거의 40분,,)
그래서 jdbc templete의 batch insert를 사용하여 배치 처리를 적용해봤다
실무에서도 대용량 데이터를 삽입을 처리할 때 이 방식을 사용한다고 한다
jdbc templete batch insert
이런식으로 하나의 쿼리문으로 여러개의 데이터를 처리해준다
INSERT INTO table (col1, col2) VALUES
(val1, val11),
(val2, val22),
(val3, val33);
properties 파일 설정 변경
- mysql의 경우 rewriteBatchedStatements=true를 적용하여 배치 처리를 허용한다고 설정한다
- batch_size를 설정해준다 -> insert쿼리를 100개 모아놨다가 한번에 보낸다는 의미
spring.datasource.url=jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true&profileSQL=true&logger=Slf4JLogger&maxQuerySizeToLog=999999
spring.jpa.properties.hibernate.jdbc.batch_size=100
UserBulkRepository
@Repository
@RequiredArgsConstructor
public class UserBulkRepository {
private final JdbcTemplate jdbcTemplate;
@Transactional
public void saveAll(List<User> users) {
String sql = "INSERT INTO users(email, image_url, nick_name, password, user_role)"
+ "VALUES (?, ?, ?, ?, ?)";
jdbcTemplate.batchUpdate(sql,
new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
User user = users.get(i);
ps.setString(1, user.getEmail());
ps.setString(2, user.getImageUrl());
ps.setString(3, user.getNickName());
ps.setString(4, user.getPassword());
ps.setString(5, String.valueOf(user.getUserRole()));
}
@Override
public int getBatchSize() {
return users.size();
}
});
}
}
TestCode
@Test
void 유저_데이터를_100만_건_생성() {
List<User> userList = new ArrayList<>();
for (long i = 0L; i < 1000000; i++){
String email = "user" + i + "@example.com";
String password = "securePassword123";
UserRole role = UserRole.of("ROLE_USER");
String nickName = UUID.randomUUID().toString().substring(0, 8);
User user = new User(email, password, role, nickName);
userList.add(user);
}
userBulkRepository.batchUpdate(userList);
}
Exception in thread "mysql-cj-abandoned-connection-cleanup" java.lang.OutOfMemoryError: Java heap space
-> 힙 메모리가 부족하다고 한다
원인
- 아무래도 BatchSize를 저장하려고 하는 데이터의 개수로 해서 부하가 온 것 같다
- BatchSize를 줄여주자
네 번째 시도 : 성공!
공식문서를 참고하여 배치사이즈를 지정하고 배치 쿼리를 적용하도록 적용해봤다
참고 : https://docs.spring.io/spring-framework/reference/data-access/jdbc/advanced.html
100개씩 쌓아놨다가 insert 수행!
@Repository
@RequiredArgsConstructor
public class UserBulkRepository {
private final JdbcTemplate jdbcTemplate;
public int[][] batchUpdate(final List<User> users) {
int[][] insertCounts = jdbcTemplate.batchUpdate(
"INSERT INTO users(email, image_url, nick_name, password, user_role)" + "VALUES (?, ?, ?, ?, ?)",
users,
100,
(PreparedStatement ps, User user) -> {
ps.setString(1, user.getEmail());
ps.setString(2, user.getImageUrl());
ps.setString(3, user.getNickName());
ps.setString(4, user.getPassword());
ps.setString(5, String.valueOf(user.getUserRole()));
});
return insertCounts;
}
}
테스트가 잘 수행됐다
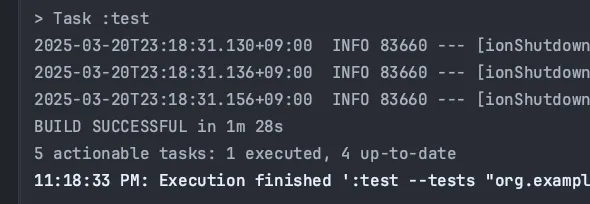
100만개를 생성하는데 총 1분 28초가 걸렸다
참고로,,,,
DB를 열어봤는데 데이터가 1000개만 조회된 것이다
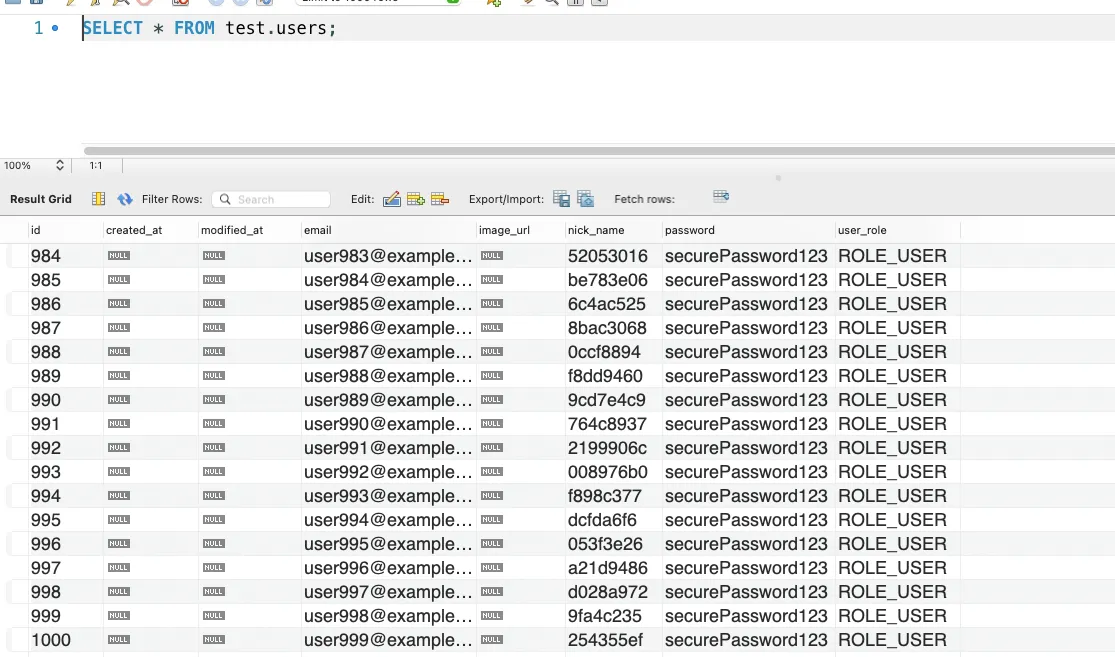
충격을 받고 계속 다른 코드를 찾아보면서 바꿔도 똑같은 결과가 나왔다…
그래서 일단 테스트 다시 할때마다 삭제를 진행해야 하기 때문에 삭제를 했다

음 삭제한 행이 백만개라고?
데이터 조회만 1000개 한거였다! 😭
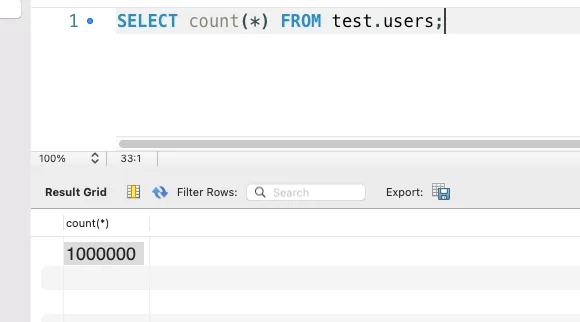
데이터는 잘 생성된 것이었다고 한다...
다음부터 이런 착각은 하지 않도록 조심해야겠다..
User데이터 100만건 검색 성능 개선
jmeter라는 테스트 도구를 사용하여 테스트를 진행해봤다
참고로 내 기준보다 여러명의 사용자가 많은 요청을 해야 성능 개선 전후의 차이를 정확하게 비교할 수 있다
실행법
설치 후 터미널에 jmeter 쳐서 실행
JMeter 성능지표
Summary Report
- Label : Sampler 명
- Samples : 샘플 실행 수 (Number of Threads X Ramp-up period)
- Average : 평균 걸린 시간 (ms)
- Min : 최소
- Max : 최대
- Std. Dev. : 표준편차
- Error % : 에러율
- Throughput : 초당 처리량 (bps) = JMeter에서는 시간 단위를 보통 TPS (Transaction Per Second)로 표현
- Received KB/sec : 초당 받은 데이터량
- Sent KB/sec : 초당 보낸 데이터량
- Avg. Bytes : 서버로부터 받은 데이터 평균
JMeter 테스트 용어
- Thread Group : 쓰레드 1개당 사용자 1명
- Sampler : 사용자의 액션 (예: 로그인, 게시물 작성, 게시물 조회 등)
- Listener : 응답을 받아 리포팅, 검증, 그래프 등 다양한 처리
- Configuration : Sampler 또는 Listener가 사용할 설정 값 (쿠키, JDBC 커넥션 등)
- Assertion : 응답 확인 방법 (응답 코드, 본문 내용 비교 등)
nickname 컬럼에 index 걸기
사용자는 nickname으로 user를 검색하기 때문에 해당 컬럼에 인덱싱을 걸어주자
인덱싱 미적용 : 평균 4872ms
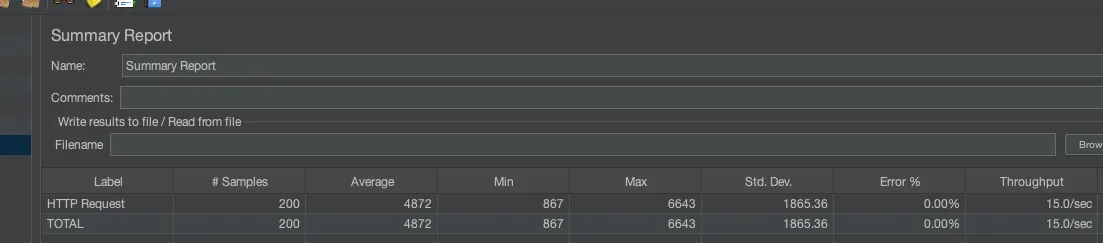
인덱싱 적용 : 평균 226ms
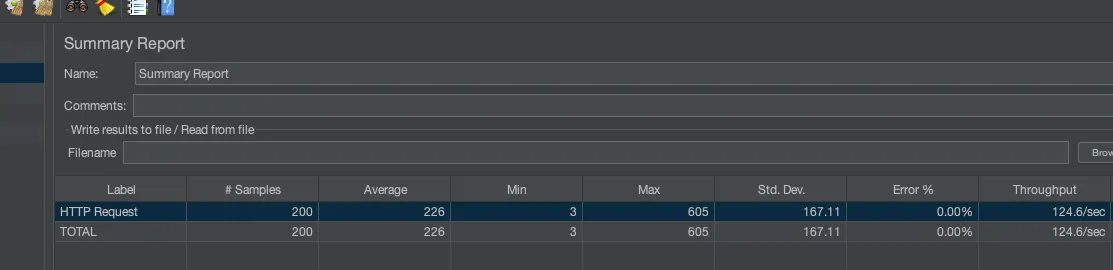
인덱싱을 적용하면 21.58배 빨라지는 것을 볼 수 있다
'Spring' 카테고리의 다른 글
| JPA와 Transaction (1) | 2025.03.21 |
|---|---|
| Spring Security의 JWT 적용 (1) | 2025.03.21 |
| intellij 프로젝트 내부에 작업물이 안 보일 때 해결방법 (0) | 2025.03.12 |
| 양방향 연관관계와 영속성 전이 (Cascade) / Fetch / 페이징 정렬 / Dynamic Insert,Update (0) | 2025.03.12 |
| 영속성(persist,merge..)과 쓰기지연 (0) | 2025.03.11 |

